
From Message to Job: A Serverless Event-Driven Data Pipeline on GCP
How to build a glorious, serverless Rube Goldberg machine that actually works.

Are you working on an app where some tasks just take too long? Such as generating a massive report, transcoding a video, or running a complex calculation. Making your user wait while this happens is a pretty shit experience. The classic solution is to do this work in the background, but that often opens a whole new can of worms around managing infrastructure for these background tasks. Now you need some kind of queuing library, an external service to store messages like Valkey (or Redis) and then some other process to run and read those messages. Well fear not because….
This is where a serverless, event-driven approach comes in handy. Today, we're going to look at a neat pattern on Google Cloud for handling this exact problem. We'll build a pipeline that takes a message from a Pub/Sub topic, uses a Cloud Function to process it, and then kicks off a Cloud Run Job to do the heavy lifting. The best part here is that the entire setup is defined using Terraform, so it's repeatable, reliable, and easy to manage.
For those of you who don’t want to read, and just want the code, I’ve open sourced it here: https://github.com/jgunnink/pubsub_function_cloudrunjob
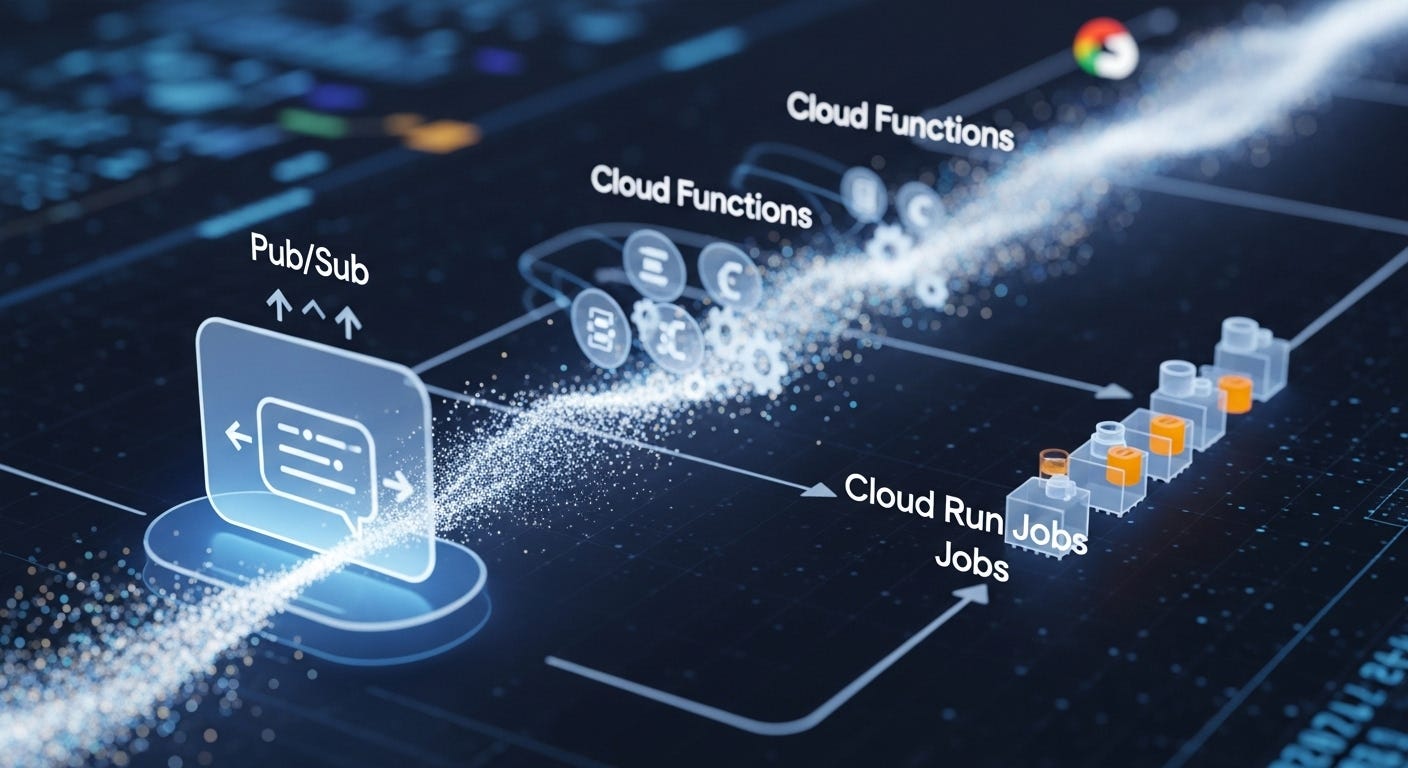
The Architecture: A Bird's-Eye View
Before we get our hands dirty, let's take a look at the components and how they fit together. You can think of it like a digital mailroom.
Pub/Sub Topic (
my-topic): This is our inbox. It's a messaging service where we can drop off “letters” (messages) without worrying about who will pick them up or when. This decouples the part of your app that requests the work from the part that does the work.Cloud Function (
my-function): This is the mail sorter. It's a small piece of Python code that automatically runs whenever a new message arrives in our Pub/Sub inbox. Its job is to open the message, figure out what needs to be done, and pass it on to the right worker.Cloud Run Job (
my-job): This is our specialist worker. It's a containerised application designed to run a specific task and then shut down3. Unlike a web service that runs continuously, a Cloud Run Job is perfect for batch processing or tasks that have a clear start and end.Terraform: This is the blueprint for our entire mailroom. Instead of clicking around in the Cloud Console, we define all our resources, in this case the topic, the function, the job, and the permissions in terraform code (HCL syntax). This means we can build, change, or completely replicate our setup with a single command, which is brilliant for consistency. We can also validate infrastructure in a non-prod environment works in a prod environment, since it’s identical.
The workflow is simple: A message is published to the topic, which triggers the function, which in turn executes the job. It's scalable, cost-effective (you only pay when it's running), and incredibly flexible.
Let's Get Real: Practical Use Cases
This pattern isn't just a cool technical exercise; it solves real-world problems. Here are a few examples of how you could use this exact architecture:
Video Transcoding: A user uploads a high-resolution video to your app. Your app publishes a message to Pub/Sub with the video's location. The Cloud Function triggers a Cloud Run Job that uses a tool like FFmpeg inside its container to create versions of the video for different devices (1080p, 720p, etc.).
Complex Report Generation: A business user requests a quarterly sales report. Instead of locking up their browser, your API sends a message to Pub/Sub. The function kicks off a job that queries multiple databases, crunches the numbers, generates a PDF, and emails it to the user.
ETL (Extract, Transform, Load) Pipelines: An external system drops a new data file into a Cloud Storage bucket. A notification triggers an event that sends a message to Pub/Sub. The function then launches a Cloud Run Job to read the file, clean and transform the data, and load it into a data warehouse like BigQuery for analysis.
Nightly Data Aggregation: A Cloud Scheduler job publishes a “start of day” message to Pub/Sub every morning. The function starts a Cloud Run Job that aggregates all the previous day's user activity into a summary table, getting your analytics dashboards ready for the business day. You could argue that you might want to start the job directly via Cloud Scheduler, and trhat would be a valid usecase, but if you’re doing any kind of message validation or transformation of the message in the function then you’d need to move the logic to the job which makes it messier for some usecases.
In all these cases, the core application remains responsive and unburdened by the heavy lifting, which is handled by our scalable, on-demand Cloud Run Jobs.
Okay, Let's Build It!
Convinced? Awesome. Let's walk through how to set this up. We won't go through every line of code, but we'll cover the key parts.
Prerequisites
Before you start, you'll need:
A Google Cloud project with billing enabled.
The
gcloudcommand-line tool installed and authenticated.Terraform installed on your machine.
The source code here, downloaded.
Step 1: The Infrastructure Blueprint (Terraform)
Our Terraform code will define everything we need. The key resources are:
Pub/Sub Topic: A simple resource to create
my-topic.GCS Bucket: A storage bucket to hold our Cloud Function's zipped source code.
Cloud Function: This resource defines our function, sets its trigger to be the Pub/Sub topic, and points to the source code in the GCS bucket.
Cloud Run Job: This defines our job, pointing to a container image. For this example, we're just using a basic Debian image (
debian:stable-slim) that prints a message, but you'd replace this with your own application's image.Service Account & IAM: This is crucial. We create a dedicated service account for the Cloud Function. We then give it permissions to invoke Cloud Run Jobs. This follows the principle of least privilege, ensuring our function can only do what it's supposed to.
Once you have your Terraform files (.tf) ready, you’ll need to zip up the function source code so it can be put in the bucket. You can zip it up however you like, but if you’re like me and prefer the command line, on a mac I just use:
zip -j cloud_function.zip cloud_function/src/*Then, once zipped, you can go ahead and deploy your infrastructure with Terraform. Deploying is as simple as running terraform init and then terraform apply.
Step 2: The Mail Sorter (The Cloud Function)
The Python function is the brains of the operation. It's surprisingly simple. When triggered, it receives the Pub/Sub message, which is Base64 encoded. The function just needs to:
Decode the message data to get the original JSON payload.
(Optional) Perform some validation or logic based on the message content.
Use the Google Cloud client library to launch the Cloud Run Job, potentially passing in data from the message as environment variables to the job's container.
Step 3: The Workhorse (The Cloud Run Job)
The Cloud Run Job itself is just a container. In our example, its ENTRYPOINT is a simple shell command: echo "Hello from the Cloud Run Job!".
In a real-world scenario, you would build a container with your application code. For the video transcoding example, you'd have a Dockerfile that installs FFmpeg and a script to perform the transcoding. The beauty is that the job can be anything you can put in a container.
Step 4: Putting It All Together & Testing
After running terraform apply, your entire pipeline is live. To test it, you can publish a message directly to your topic from the command line:
gcloud pubsub topics publish my-topic --message '{"user_id": "123", "report_name": "quarterly_sales"}'
Now, check the logs for your Cloud Run Job. You should see a new execution has started and completed, with the "Hello from the Cloud Run Job!" message in its output, along with the message’s userId and report_name. Success! 🎉
Final Thoughts
This serverless, event-driven pattern is a powerful tool to have in your cloud engineering toolbox. It allows you to build sophisticated, robust, and scalable background processing systems without ever having to think about managing a server. By combining Pub/Sub, Cloud Functions, and Cloud Run Jobs and managing it all with Terraform you can focus on writing code that delivers value, not on wrangling infrastructure. Worth mentioning too, that this infrastructure will manage itself as it’s all hands off and manged for you as part of the cloud offering. Dirt cheap too. My favourite things about serverless. Just pay for what you use, when you’re using it.
I love that you've incorporated IaC into the demo mate. Great work once again!